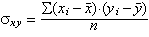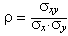|
|||||||||||||||||
| Pràctica |
|
|
|
|
|
|
Exercicis
|
|
|||||||||
|
|
Glossari
|
|
|||||||||||||||
| L'estadística bivariant
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
La recollida de dades bivariants (o multivariants) en una població té com una de les seves principals finalitats l'estudi conjunt de dues variables. En estudis d'aquest tipus es considera com a fonamental la recerca de relacions entre les variables que permetin inferències posteriors. Cal comentar d'antuvi la diferència essencial entre la relació funcional i la relació estadística: no s'ha de tendir a buscar fórmules estrictes, sinó, més aviat, cal pensar en tendències en l'associació de valors que permeten predir què pot succeir quan s'examinen aquestes mateixes variables en una altra població. Pel que fa a la recollida de dades d'una distribució estadística bivariant, hem de fer notar que ha de ser feta de tal manera que per cada individu de la població s'hagi observat i mesurat el valor de dues (o més) variables que s'han enregistrat associades. Analitzarem un exemple per aclarir aquesta idea.
Tot seguit, comencem l'estudi pràctic de presentació de dades de l'estadística bivariant. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Taules creuades | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Per fer estadística bivariant cal presentar els resultats de la tabulació en forma de taules creuades (dites també de doble entrada o de contingència), en què es fa avinent la manera de recollir les dades: dades emparellades; sobre cada individu de la població estadística en estudi s'han observat els valors de dues variables.
Vegeu un exemple de taula creuada que es correspon a les que hem analitzat anteriorment:
Adoneu-vos que, a partir de les dades creuades, es poden construir les distribucions marginals, però no al revés. Amb una taula creuada ja es poden estudiar les relacions entre les dues variables. Per analitzar el comportament conjunt de les dues variables interessa constatar si hi ha una associació de valors, és a dir, si es pot observar que algun(s) valor(s) d'una variable tendeixen a aparèixer emparellats amb algun(s) valor(s) de l'altra variable. A l'exemple veuríem que els insuficients d'una matèria "tendeixen a ser" insuficients de l'altra; també els aprovats; també les bones notes... (i això és el que ens fa dir intuïtivament que "hi ha relació" entre els rendiments en les dues assignatures). Però també es pot veure que hi ha força discrepàncies. Tots aquests aspectes són els que no es podrien analitzar, de cap manera, només amb les distribucions marginals.
Vegeu la taula de percentatges per files corresponent a l'exemple que analitzem. Aquesta taula respon a la pregunta: Quin és el rendiment en llengua castellana segons la nota obtinguda en llengua catalana?
L'apartat següent mostra un altre exemple de la utilitat dels percentatges per files o per columnes per analitzar les relacions entre variables o la influència d'una sobre una altra. Les taules creuades, tant amb freqüències absolutes o percentatges globals com les que mostren els percentatges per files o per columnes, es fan visuals amb els diagrames de barres combinats, ja presentats en el mòdul 1. Tant el treball amb taules creuades com la realització de diagrames de barres amb l'Excel es treballen a les pràctiques 1 i 2 d'aquest mòdul. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Causalitat o casualitat? | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Ja hem dit que en els estudis bivariants es busquen relacions entre les variables i hem comentat que això no s'esdevé amb fórmules estrictes, sinó que cal pensar en tendències en l'associació de valors. Hi ha dues maneres d'enfocar el problema de les relacions entre variables:
A més de veure un exemple d'aquest darrer enfocament del problema de les relacions entre variables, en aquest apartat comentarem la precaució amb què s'ha d'anar quan es desenvolupen estudis de relacions entre variables per analitzar correctament la realitat. Es presenta seguidament un exemple, adaptat de Moore. S., Statistics and Controversies, on es dóna una visió simplificada d'una situació real.
La meitat dels homes que es presentaven han estat admesos, però, en canvi, només la tercera part de les dones! Sembla clar que hi ha discriminació! (És a dir, que la variable sexe té una influència clara sobre la variable apte / no apte.) Ara mirarem més a fons el problema, aportant-hi dades noves. La universitat respon que, tot i que es pot creure que l'associació de valors observada és correcta, el que no és cert és que sigui deguda a la discriminació, i per a justificar-ho presenta unes taules on es consideren els tres factors que intervenen, sexe, admissió o no, i també el curs al qual s'havia apuntat cadascú. Unes dades com aquestes es presenten com diverses taules de doble entrada, una per cada valor de la tercera variable. En aquest cas hi ha dues taules, una per cada curs de postgrau.
Adoneu-vos que realment aquestes dades concorden amb les inicials. La universitat simplement ha reproduït la taula inicial però desglossada per departaments, sense ajuntar-la en una de sola. Vegem les taules de percentatges per files que permetran estudiar la influència del sexe en l'admissió. En aquest cas, tal com s'han presentat les taules, ens interessen els perfils fila.
Així, veiem que al curs d'enginyeria s'han admès el 60 % dels sol·licitants, tant pel que fa als homes com pel que fa a les dones. Semblantment passa a filologia: el 20 % d'admesos. Per tant, és del tot clar que no hi ha associació entre el sexe i la decisió sobre l'admissió en cap dels dos cursos. Per veure això ens adonem que els percentatges per columnes són idèntics en un cas o en l'altre. Com pot ser que si no hi ha associació de valors en cap dels dos cursos, quan s'ajunten les dades hi ha una aparença d'associació de valors home-apte i dona-no apta? Senzillament, és difícil entrar al curs de filologia on s'hi preinscriuen moltes dones; és fàcil ser admès al curs d'enginyeria, i aquest el demanen molts homes. Tot i que l'exemple anterior pot semblar massa senzill per representar una situació real, sí que ens ha de servir per comprovar:
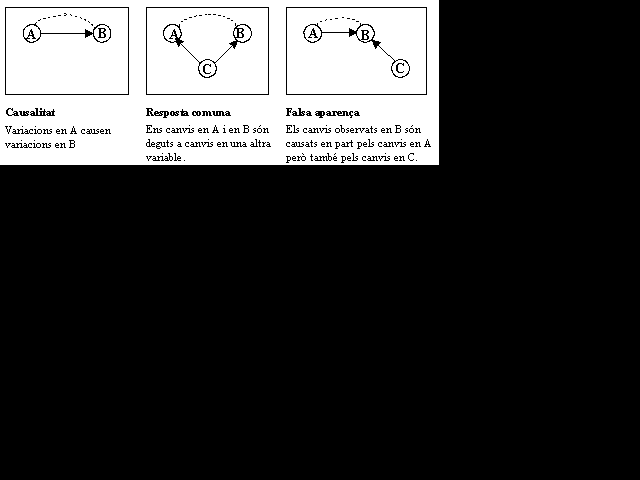
Moltes vegades s'intenten establir relacions de tipus causal entre dues variables. Convé observar que quan es volen establir associacions s'ha d'anar molt amb compte abans de treure una conclusió definitiva, que moltes vegades anirà molt més enllà del marc del treball estadístic, tal com ha quedat esquematitzat a l'exemple anterior. Els gràfics següents mostren diverses situacions que es poden presentar quan hom troba que hi ha un lligam o associació entre dues variables A i B, que s'ha representat per la línia de punts:
Qualsevol experiència que tendeixi a establir relacions de causa-efecte entre variables ha de ser repetida en circumstàncies ben diferents; així, es pot constatar que, realment, a la vista de les dades recollides, és plausible que determinats valors d'una de les variables estiguin efectivament associats amb determinats valors de l'altra, però, al mateix temps, fer avinent que no es tracti de falses aparences o que no hi hagi un factor extern que influeixi en les dues variables estudiades. És clàssic, en aquest sentit, l'exemple d'una població nòrdica on, degut a l'època de les migracions de les aus i al ritme de natalitat, hi ha una correlació molt elevada entre el nombre de naixements cada mes i el nombre de cigonyes que nien al campanar d'aquella població. Podem deduir d'això que les cigonyes porten els nens? Abans de passar a fer càlculs per estudiar les relacions entre variables hem de tenir molt en compte el que s'acaba de dir; que no ens passi que els càlculs numèrics que exposarem als apartats següent ens enceguin i no analitzem prou bé la realitat... fins al punt que encara hi ha un altre tipus d'associació de variables que es pot donar a la vista dels números: uns valors que mostrin una aparença de lligam o relació poden ser fruit no de la causalitat, sinó de la casualitat! |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Correlació | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
En aquest apartat presentarem des d'un punt de vista conceptual els procediments gràfics i numèrics per estudiar la relació entre dues variables numèriques. Per veure com es poden dur a la pràctica amb l'Excel, consulteu la pràctica 3 d'aquest mòdul. Per a l'estudi inicial es recomana sempre fer en primer lloc un gràfic, anomenat sovint núvol de punts, que permet fer visual el comportament global d'una distribució bidimensional de dues variables numèriques. A la vista del núvol de punts, es poden fer ben avinents algunes característiques de la població que poden fer necessari un estudi especial. Per exemple, l'existència de dues o més sub-poblacions diferenciades que calgui treballar separadament. La primera observació que s'acostuma a fer per estudiar les relacions entre variables numèriques és la de constatar si hi ha una tendència a l'associació dels valors grans d'una variable amb els valors grans de l'altra (associació positiva) o bé dels valors grans d'una variable amb els valors petits de l'altra (associació negativa) o bé no es constata cap associació significativa de valors. Per posar de manifest alguna d'aquestes associacions es recomana dibuixar, pel punt mitjà de la distribució, paral·leles als eixos. Hi ha associació positiva quan la major part dels punts del núvol queden al primer i al tercer quadrant determinats per aquestes paral·leles; hi ha associació negativa quan la major part de punts queden al segon i al quart quadrant; si els punts es dispersen per tots els quadrants, no s'observa relació. Vegeu la pràctica 6. Després de comprovar que els valors d'una variable s'associen amb determinats valors de l'altra, hom es pregunta de seguida si es podria mesurar numèricament el grau de relació o interdependència que se sospita que hi ha entre dues variables. Per això es defineixen els coeficients de correlació. En estadística es consideren diversos coeficients d'aquest tipus, que depenen de la manera com s'estudiï la possible relació, però que tenen diverses característiques comunes:
Tot seguit, introduirem conceptualment alguns d'aquests coeficients de correlació. En primer lloc, veurem el coeficient de correlació lineal (de Pearson), possiblement el més emprat en estudis superiors. També s'empren alguns coeficients de correlació no paramètrics, que tenen en compte només l'ordenació de valors i, doncs, corresponen a un tipus de treball d'estil anàleg al que es fa amb la mediana i els quartils. S'explica el coeficient de correlació de Spearman.
Això es constata sobre el núvol de punts per l'agrupament dels punts molt a prop d'una línia recta. Ja s'ha dit quin és el rang de valors possibles d'aquest coeficient; els valors extrems, +1 i –1, indiquen el tipus d'associació perfectament definits per una línia recta (creixent o decreixent, respectivament). Entremig d'aquests dos valors extrems, el coeficient de correlació mesura si els punts representats en el núvol tendeixen a agrupar-se entorn d'una línia recta de manera molt estricta o amb volta variabilitat. A la pràctica 6 veureu recursos didàctics que ajuden a analitzar, a la vista del núvol de punts, el valor del coeficient de correlació lineal i entendre què representa i què no hi és considerat. Es pot observar que hi ha una coincidència en el signe del coeficient de correlació lineal i el signe del pendent de la recta entorn a la qual es poden considerar agrupats els punts de la distribució. Ara bé, la coincidència no s'estén pas als valors absoluts del pendent de la recta i del coeficient de correlació.
Tot seguit es calcula la covariància, nombre que mesura la variació conjunta global de les dues variables.
Per tant, de manera semblant a què es fa amb el procés d'estandardització, convé passar a un altre valor que mesuri la relació intrínseca entre les variables, independentment de les unitats. És per això que, de fet, es calcula la covariància entre les variables estandarditzades, se simplifica l'expressió que resulta i s'obté la fórmula següent:
Seguidament, donem algunes observacions sobre el coeficient de correlació lineal que acabem de definir que podeu constatar amb les pràctiques.
De la mateixa manera que en l'estadística univariant, es consideren la mediana i els quartils, que es basen fonamentalment en l'ordenació de les dades i no en els seus valors reals, i per això reben el nom de no paramètrics. Es defineixen també coeficients de correlació en aquest àmbit de treball; el més emprat és el coeficient de correlació de Spearman. Consisteix, essencialment, a comparar els rangs que es poden assignar als individus de la població per una de les variables amb els rangs corresponents a l'altra. En aquest cas, el valor 1 de coeficient de correlació indica que s'ha trobat, exactament, el mateix ordre, i el valor -1 indica que s'ha trobat, exactament, l'ordre invers en una variable que en l'altra.
Observació:
La fórmula resulta de fer un còmput del total de la discrepància
entre els rangs (valors assignats a les dades de cada conjunt per les
respectives ordenacions), feta positiva pel quadrat i després sumada;
de comparar aquesta discrepància amb el màxim valor que
podria tenir (que es calcula algebraicament en funció de n)
i, finalment, de canviar l'escala perquè l'abast dels valors del
coeficient vagi de –1 fins a +1. Com que el coeficient de Spearman té en compte exclusivament l'ordre dels valors observats de les variables els valors extrems -ni que siguin atípics- no influeixen decisivament en el càlcul d'aquest coeficient. Vegeu un exemple del tipus de situacions en què s'aplica aquest coeficient. Dos jurats diferents han valorat deu treballs presentats i la taula següent mostra les puntuacions que han atorgat a cada treball:
Per computar el coeficient de correlació de Spearman, només interessen els rangs o classificacions ordenades de cada valoració:
Ara s'aplicaria la fórmula i s'obtindria c = 0,7727.
Finalment, plantegem-nos una pregunta. Ja hem calculat un coeficient de correlació. El valor que hem obtingut, és molt o és poc? Per rigoritzar la resposta a aquesta qüestió cal enfocar-la en el marc de les proves de contrast estadístic. Tanmateix, s'acostuma a entendre que un coeficient de correlació lineal de valor absolut superior a 0,7 indica una plausibilitat del model lineal per descriure el conjunt de dades o bé, en el cas del coeficient de correlació de Spearman, una acceptable concordança de les valoracions. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Models per explicar la relació entre variables numèriques | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Una de les fites que es marca el treball científic, i també, doncs, l'estadística, és la possibilitat de predir resultats d'allò que pot passar quan es donen circumstàncies semblants a les ja estudiades. Amb aquesta idea sorgeix el concepte de regressió, que rep el nom a partir d'una experiència de relacions entre variables duta a terme per Sir Francis Galton (1822-1911). A la pràctica 5 d'aquest mòdul la teniu exemplificada. Es tracta d'establir, en el marc de l'estadística bivariant, una funció que permeti descriure de la millor manera possible la relació entre les variables i estimar el valor que pot tenir una de les variables (dita variable resposta) per a un element del que s'ha pogut mesurar el valor de l'altra variable (dita variable d'entrada o predictora). Convé proporcionar vocabulari:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| La recta de regressió | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
La recerca d'un model per descriure les relacions entre variables comença amb les funcions de manipulació més senzilla: les funcions lineals. Quan hom s'ha convençut de la bondat d'un estudi del núvol de punts d'una distribució bivariant mitjançant una línia recta, de primer intuïtivament sobre el gràfic, i posteriorment amb el càlcul del coeficient de correlació, convé saber la forma adequada de dibuixar la recta que millor descriu la relació entre les variables. Aquesta recta rep el nom de recta de regressió. La primera possibilitat intuïtiva per dibuixar la recta, com a primer supòsit, pot ser fer-ho a ull, mirant d'entendre quina és la recta que millor s'adapta al núvol de punts. Hi ha també d'altres mètodes descriptius, però, amb l'ajut de l'Excel, podem anar directament a obtenir la recta que, realment, dóna un millor ajust.
Observeu allò que ja s'havia comentat, a saber, que el signe del pendent de la recta de regressió coincideix amb el signe del coeficient de correlació. De fet, aquests dos nombres tenen el signe de la covariància.
Una vegada establert el model, en aquest cas el que ens dóna la recta de regressió, podem fer prediccions del valor que pot tenir la variable de resposta. El valor que ens dóna la funció model, per a un cert valor x0, és a dir, el que hem definit com a ajust, és el valor que estimarem. Per exemple, les màquines de pesar que podem trobar al metro o en algunes farmàcies, que comparen el pes que obtenen amb un anomenat pes ideal (després de preguntar dades d'alçada, edat, etcètera), fan prediccions a partir d'un estudi de regressió. En algunes de les pràctiques d'aquest mòdul treballareu aquest tema. Atès que el coeficient de correlació de Pearson mesura com d'estricte és l'acostament del núvol de punts a una línia recta, és ben intuïtiu que, com més gran és el valor absolut del coeficient més fiabilitat tenen les prediccions que es poden fer i més petit és el marge d'error amb què cal enunciar-les. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Altres tipus de regressió | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Quan el model lineal no apareix com a fiable, per a deduccions posteriors es pot acudir a l'estudi d'altres models, d'altres funcions que siguin les que millor s'ajusten al núvol de punts. En alguns textos es parla molt amb detall de la regressió parabòlica, però en general es considera més interessant l'estudi de la correlació i la regressió lineal entre les variables i els seus logaritmes, com s'exemplifica a la pràctica 5. Els models que s'estudien són aquests:
També es considera de vegades un altre model de regressió simple, que s'anomena model recíproc, en el qual estudia la correlació lineal entre x i 1/y. I no es pot acabar aquest apartat sense indicar que, en estudis superiors, s'ha de donar molta importància a la regressió múltiple, en què hom intenta establir numèricament la significativitat de la influència de diverses variables d'entrada o predictores sobre la variable de resposta. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||