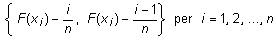| |
|
||||||||||||||||
| Pràctica |
|
|
|
|
|
|
Exercicis
|
|
||||||||
| Els contrastos d'hipòtesis.
La prova khi quadrat |
Glossari
|
|
||||||||||||||
| Proves de normalitat |
|
| En aquest document tenim en compte el fet que
en moltes situacions pràctiques cal prendre com a hipòtesi de treball la
consistència del model normal per a un conjunt de dades.
 Les proves de normalitat quantifiquen la validesa del model normal A la primera part del document es comenta la possibilitat d'emprar la
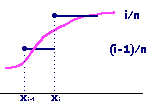
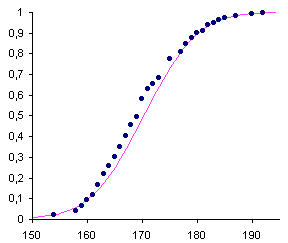
prova de Per aquesta raó, hi ha tot un conjunt de proves de contrast que es basen en els valors de totes i cadascuna de les dades observades, i a partir d'elles consideren la funció de freqüències absolutes acumulades observades (és a dir, empíriques) que confronten amb la funció de distribució teòrica del model normal. Entre aquestes s'explica amb detall la prova de Kolmogorov-Smirnov, la que està més al nostre abast des del punt de vista conceptual i procedimental, i es comenta la d'Anderson-Darling. |
|
| |
La prova de
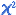 , sí o no? , sí o no?
En el primer document conceptual del mòdul, hem vist la utilitat de la prova de khi quadrat per valorar la bondat de l'ajust d'un conjunt de dades categòriques o bé numèriques discretes mitjançant un model de probabilitat. Les primeres pràctiques del mòdul ens ajuden a consolidar aquests continguts. En alguns textos o programes d'ordinador suggereixen emprar també la prova de khi quadrat en el cas de variables contínues. A la pràctica 5 ho experimentarem a partir de diversos exemples en l'entorn de l'Excel (que elaborarem a mà perquè el programa no incorpora aquest procediment com a tal en la situació que ara ens ocupa). A la pràctica veurem de seguida un gran però que, per a
les variables contínues, ens ha de portar a usar Per dur a terme el test de
Per aquesta raó, amb l'objectiu de valorar el grau de significació de l'ajust per una distribució normal d'un conjunt de dades corresponent a una variable aleatòria contínua, es busquen models teòrics que no incorporin l'agrupació en classes. Tanmateix, en algunes altres situacions, les dades d'una variable contínua
ja les trobem agrupades en intervals i ja estan tabulades. En aquestes
condicions, sí que cal aplicar la prova de khi quadrat (amb l'únic i necessari
control que les freqüències esperades en cada classe siguin de 5 o més)
i aquest procediment serà del tot significatiu. Si només disposem de la
taula de freqüències observades agrupades en classes, no tenim informació
suficient per fer altra cosa. |
| |
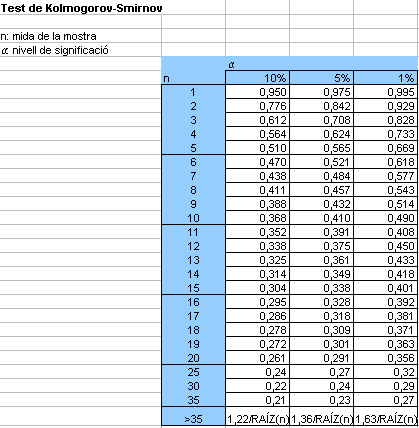
La prova
de Kolmogorov-Smirnov de la bondat de l'ajust
A diferència del test de khi quadrat que, com acabem de dir, aplicat a una variable contínua presenta l'inconvenient de l'arbitrarietat i la pèrdua d'informació que comporta la partició de la mostra en grups de dades, les proves de normalitat més habituals (i d'ajust amb altres distribucions de probabilitat contínues) tenen en compte el valor de cadascuna de les dades. Per altra banda, per al test de kui quadrat necessitem un conjunt nombrós de dades, cosa que no succeeix en la prova de Kolmogorov-Smirnov, que presentem en aquest apartat i que es pot aplicar a conjunts no gaire nombrosos.
|
| |
Quina és la millor prova
de bondat de l'ajust?
En la literatura estadística trobareu documentades moltes proves de normalitat. Feu una prova: escriviu al Google normality test o també prueba normalidad i tindreu clara constància del que diem. Tanmateix, l'explicació detallada de moltes d'aquestes proves escapa dels objectius d'aquest curs (i dels coneixements dels autors). Per altra banda, convé comentar que, com que cada prova fa servir un estadístic diferent, les conclusions no són sempre coincidents (si fos així, només faria falta un test!). L'estudi de les diverses situacions en què convé aplicar un test o un altre (fins i tot dels que s'han comentat), ens portaria a un elaborat tractat d'estadística, i aquest no és pas un objectiu que ens hàgim marcat.
|
|
Com a norma general (excepte
si el conjunt de dades és molt i molt nombrós), es pot dir que el test de
Kolmogorov-Smirnov és força tolerant (potser això recomanaria aplicar-lo
amb més nivell de significació del que és habitual), i en canvi, el que
presentem com a ampliació, el d'Anderson-Darling, tot i que també es basa
en la discrepància entre la distribució empírica i la teòrica, és molt més
exigent.
|
|
|
|
| Ampliacions, aclariments i comentaris | |
| |
La
prova de normalitat d'Anderson-Darling
Aquesta és una prova inclosa en el grup de proves de la bondat de l'ajust que es basen, com la de Kolmogorov-Smirnov que s'ha explicat amb detall, en l'intent de mesurar la discrepància entre la funció que dóna les freqüències relatives acumulades de la distribució empírica de les dades recollides i la funció de distribució que dóna la probabilitat acumulada en el model teòric. Representarem com a G(x) i F(x), respectivament, les dues funcions indicades anteriorment. Hi ha una família d'estadístics que valoren aquesta discrepància, que rep el nom de Cramér-von Mises i que estan formulats, de manera general, així:
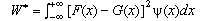 En el cas de la prova d'Anderson-Darling, l'estadístic es defineix mitjançant la funció de ponderació següent:
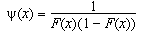 Per tant, és interessant tenir-ho en compte per emprar el test d'Anderson-Darling i pensar que moltes altres proves de normalitat vigilen molt contra una excessiva influència dels valors extrems.
|
|
|
|
 per dur a terme el contrast, i
s'explica que el principal inconvenient apareix a partir de la subjectivitat
en l'elecció de les classes.
per dur a terme el contrast, i
s'explica que el principal inconvenient apareix a partir de la subjectivitat
en l'elecció de les classes.
 x1
x1