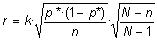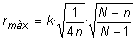|
||||||||||||||||
| Pràctica |
|
|
|
|
|
|
Exercicis
|
|
||||||||
| Teorema del límit central. Estimació d'una mitjana |
Glossari
|
|
||||||||||||||
|
Idees sobre estimació. Estimació d'una proporció Al mòdul 1 es comentava el marc general de treball de l'estadística i es deia que l'ajustament d'unes dades a un model teòric per poder inferir conclusions és una tasca habitual. Hem vist al mòdul anterior uns exemples de contrastos d'hipòtesis, amb la idea concreta de confrontar la validesa d'un model. En alguns d'aquests casos, les característiques del model s'han deduït de les pròpies dades: hem fet una inferència. L'objectiu d'aquest document és presentar, des d'un punt de vista intuïtiu, els aspectes més importants relacionats amb l'estimació de paràmetres i estudiar més a fons l'estimació d'una proporció.
|
|||||||||||||||
| El marc general de l'estimació | |||||||||||||||
|
La determinació d'un paràmetre és una de les fites que habitualment es marca el procés estadístic. Tanmateix, la determinació exacta d'un paràmetre només es pot fer a partir de l'anàlisi exhaustiva de tota la població, moltes vegades fora de l'abast de l'investigador (per raons de temps, de despeses...). Llavors és quan la inferència es fa imprescindible: s'escull una mostra que sigui representativa de la població i que es pugui analitzar amb detall i a partir d'aquesta selecció i anàlisi s'estima un valor per al paràmetre que interessa.
Vegeu l'exemple següent:
Per poder arribar a una estimació a partir de l'estadístic escollit, ens caldria conèixer el model teòric que explica la seva variabilitat, calculada suposant la població coneguda. Això es pot fer amb raonaments teòrics (que escapen de la finalitat d'aquest curs) o bé amb procediments empírics, amb l'ajut d'un ordinador que ens permeti fer simulacions i prendre moltes mostres. En aquest cas, per fonamentar la inferència (pas de l'estadístic mesurat sobre la mostra al paràmetre desconegut de la població), abans es fa una simulació, a manera de treball de laboratori: es parteix d'una població coneguda, es prenen moltes i moltes mostres i s'observa com varia l'estadístic escollit. Així es pot veure si servirà com a estimador i quin tipus de garanties tindrem quan fem una estimació a partir d'una mostra.
Aquesta opció empírica és la que adoptarem, amb l'ajut de les simulacions que podem fer amb l'Excel, per a la presentació dels dos problemes fonamentals d'estimació de paràmetres. Podeu veure a la pràctica 1 un estudi del problema del bombo que s'acaba de comentar. Convé que esmentem dos conceptes importants que ajuden en la decisió de quin és el millor estimador.
Entre diversos estimadors, la consideració de l'existència de biaix o no i la comparació de la precisió és el que ens fa decidir per un o altre.
Els diagrames següents il·lustren la idea de biaix i precisió aplicats a unes persones que es dediquen a llançar dards cap a una diana. 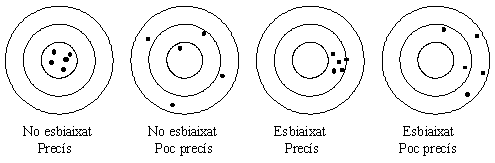
Quin d'aquests jugadors diríem que és un millor llançador? Sense cap dubte, el primer. I el segon millor? Potser ja dubtaríem entre el segon o el tercer. Ben segur que tots ens posaríem d'acord que el pitjor és el quart.Podem preguntar-nos quin hem de considerar que és el millor estimador? Per donar una resposta intuïtiva a aquesta pregunta, ens poden ajudar les simulacions i llavors entre dos estimadors que puguem observar que no tenen biaix sempre escollirem el més precís. Entre dos estimadors de la mateixa precisió sempre en triarem un que no tingui biaix enfront d'un que en tingui. Algunes vegades, però, s'opta per un estimador una mica esbiaixat, però molt precís enfront d'un altre sense biaix però poc precís. I, una vegada decidit quin és el millor estimador, com anunciarem el resultat de la nostra estimació?
Ara bé, la lectora o el lector, que ja estan a aquestes altures força familiaritzats amb la tasca estadística, pensaran que aquesta estimació ha d'anar acompanyada de la informació del marge d'error (o grau de variabilitat) que pot tenir aquesta estimació. I així és, en efecte.
Acabem aquest apartat introductori recordant el que dèiem al mòdul anterior: l'estudi de la plausibilitat d'un model mitjançant un contrast d'hipòtesis (per exemple, el test de khi quadrat) ja és una forma d'inferència. Donem com a exemple el tipus de resposta (sense parar atenció en els números) que caldria donar per a cadascun dels tres models d'inferència que hem comentat per a l'estimació del nombre de boles que hi ha al bombo:
|
|||||||||||||||
| |
Estimació d'una proporció | ||||||||||||||
| Revisió del problema de la predicció en el càlcul de probabilitats | |||||||||||||||
|
|
Per avançar en el camí que porta a l'estimació d'una proporció, us recomanem que feu la pràctica 3 en el marc de la qual es defineixen intuïtivament i de manera empírica, mitjançant simulacions, els conceptes següents, referits a l'estimació d'una proporció: Tot seguit, revisarem un exemple que ja hem treballat anteriorment al mòdul 4 per a mostres petites i, posteriorment, al mòdul 5 per a mostres grans. Podeu veure la pràctica 2 del mòdul 4 on s'han calculat probabilitats i valors crítics i la pràctica 3 del mòdul 5 on s'ha reprès l'exemple fent servir l'aproximació de la distribució binomial mitjançant la normal. Allà hem fet problemes de probabilitats a partir de models coneguts i hem fet prediccions de possibles resultats, acompanyades de la probabilitat d'encert que teníem amb aquestes prediccions. Ara reescriurem l'exemple esmentat des d'un punt de vista més formal. Exemple: En una població, el 47 % de les persones són favorables a la gestió de l'ajuntament. Si s'encarrega una enquesta que s'ha de fer a una mostra de 2.000 persones, quina és la predicció que podem fer, amb una probabilitat d'encert del 95 %, respecte a la proporció mostral?
Si s'estudia formalment una situació anàloga a la que es planteja a l'exemple, s'arriba al resultat que s'enuncia a continuació. Podeu consultar la deducció i hi veureu per què és habitual, actualment, prendre un nivell de confiança del 95,5 %.
|
||||||||||||||
|
Exemple: En una empresa en què els estudis previs demostren que el 4 % de la producció resulta defectuosa, se selecciona una mostra de 1.000 unitats. Quina previsió podem fer d'unitats defectuoses en la mostra seleccionada amb un nivell de confiança del 95,5 %?
|
|||||||||||||||
| El problema inferencial: estimació d'una proporció | |||||||||||||||
| Ja hem comentat diverses vegades
que la visió del procés d'estimació és l'invers:
no es parteix d'una població coneguda, sinó que, precisament,
es tracta d'estimar-ne un paràmetre a la vista d'una mostra. Ara
estudiarem aquesta situació, la pròpia dels problemes d'inferència que tractem
en aquest mòdul.
|
|||||||||||||||
|
|
Per a una justificació del procediment que acabem de comentar, que es concreta en l'enunciat que es dóna seguidament, podeu consultar la part d'ampliació, on veureu les precisions que cal fer, la principal de les quals és que es tracta d'una excel·lent aproximació i no d'un resultat exacte.
Hi ha un altre aspecte que és important precisar pel que fa a la validesa del resultat que acabem d'enunciar. S'ha indicat que la selecció es feia amb una mostra aleatòria simple. Aquesta suposició és equivalent a la de l'experiment de treure boles d'una bossa a l'atzar i amb reemplaçament. Tanmateix, a la pràctica, aquest no és el costum més habitual, sinó que per raons de l'eficàcia del procés de selecció es fan altres tipus de procediments de mostreig (mostres sistemàtiques, mostres per conglomerats...) i llavors el procediment cal modelitzar-lo més aviat mitjançant la distribució hipergeomètrica, que regula les experiències d'extraccions sense reemplaçament. Si es fa així, cal tenir en compte la mida de la mostra, però, si la mostra és relativament gran, les diferències no són substancials. Podeu veure les fórmules si cliqueu a la icona d'ampliació i podeu treballar el tema, a bastament, a la pràctica 4 d'aquest mòdul. Exemple: En una enquesta feta a 1.200 persones, 333 s'han mostrat partidàries d'una determinada opció. Quina estimació podem fer amb un nivell de confiança del 95,5 %?
Hem vist com es dóna l'interval de confiança d'una estimació, amb el seu valor central (proporció observada a la mostra) i el radi de l'interval (també anomenat marge d'error). Tanmateix, escau moltes vegades que un estudi estadístic (com és ara una enquesta) no es limiti a l'estimació d'una única proporció. Llavors, com que el radi de l'interval de confiança tal com l'hem vist depèn del valor observat, cadascuna de les estimacions (enunciada com a puntual per comoditat encara que això no sigui correcte conceptualment) tindria un marge d'error diferent. Això faria que la publicació de resultats fos molt enfarfegadora i també faria imprevisibles a priori els marges d'error amb què es treballaria.
|
||||||||||||||
Observació:
No s'ha de confondre marge d'error de l'estimació, que és
el radi de l'interval de confiança, concepte lligat amb el tipus
de previsions que pot fer l'estadística, que no són mai exactes,
amb risc d'error, concepte contrari al de nivell de confiança
que resulta de la influència de l'atzar en les experiències
de mostratge que no ens permet mai fer cap previsió segura. Per evitar
l'ús de dues accepcions diferents del mot error, suggerim
les dues expressions que es donen tot seguit.
|
|||||||||||||||
| Exemples:
Ara bé, allò que estimem és una proporció; en aquesta estimació, el marge d'error és el mateix (en percentatge!) en els tres casos, però heu de tenir ben present que un error relatiu del 3 % sobre la població dels Estats Units o un error relatiu del 3 % sobre la població de Barcelona donen errors absoluts ben diferents! Podeu veure que els càlculs relatius a la mida de la mostra, l'interval de confiança i el marge d'error en l'estimació d'una proporció es fan ràpidament amb l'aplicació d'una fórmula.
|
|||||||||||||||
|
|
|||||||||||||||
|
|
Ampliació 1: Deducció de la fórmula de l'interval de tolerència |
||||||||||||||
| Per enunciar-ho amb tot rigor, el que veurem
és la deducció de la fórmula que dóna l'interval de
tolerància (també dit actualment de confiança) en la previsió
del resultat de la proporció mostral en una simulació.
Si es pren una mostra aleatòria de mida n a partir d'una població en què un determinat caràcter es manifesta amb una proporció p, la distribució que representa la variable aleatòria X (nombre d'elements de la mostra que manifesten el caràcter estudiat) és una distribució binomial B(n, p) que pot ser aproximada per la distribució normal de mitjana n · p, i desviació estàndard 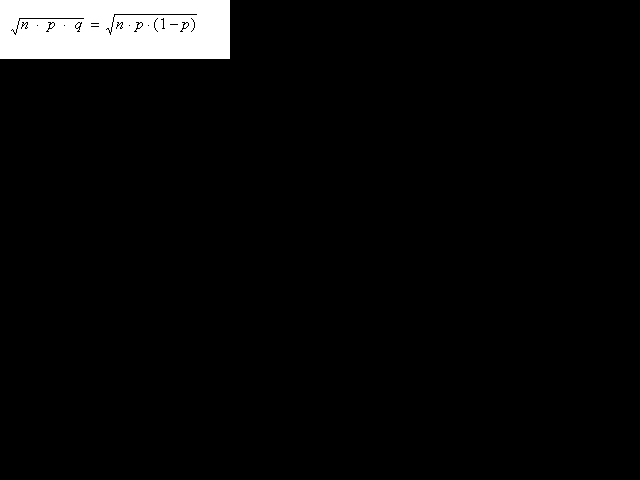
Ara bé, la proporció mostral és p* = X/n. Si en la fórmula que ens dóna la variable estandarditzada Z substituïm la mitjana i la desviació estàndard pels seus valors i dividim numerador i denominador per n queda:
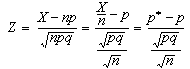

 Z 2] = 0.955 = 95,5% Z 2] = 0.955 = 95,5%
És a dir, que, en el nostre experiment, l'interval de tolerància (o de confiança) del 95,5 %, això és, el conjunt C de valors més plausibles de p* de manera que la probabilitat p[ p* pertany a C] = 0.955 = 95,5 %, són els que compleixen:
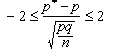
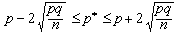
Observació
|
|||||||||||||||
|
|
|||||||||||||||
|
|
Ampliació 2: Deducció de la fórmula de l'interval de confiança |
||||||||||||||
| Per deduir la fórmula que dóna
l'interval de confiança en l'estimació d'una proporció,
podem veure que si en la fórmula que dóna l'interval de tolerància
i que s'ha deduït anteriorment fem unes transformacions algebraiques
senzilles arribem a aquesta expressió:
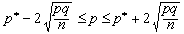
Tanmateix, es demostra que si la mostra és prou gran, es pot
prendre com a negligible la diferència entre prendre el radi de
l'interval amb la veritable desviació estàndard de la distribució,
és a dir, La diferència conceptual ve, llavors, del fet que si en el procés d'estimació fem servir p* en lloc de la p desconeguda, la proporció mostral no segueix una distribució binomial (que si n és prou gran, es pot aproximar per una normal), sinó una distribució anomenada t de Student amb n – 1 graus de llibertat, en què n és la mida de la mostra. I llavors, quin valor caldria posar en lloc del 2 (que vol dir 2,00) que assenyala el radi que dóna l'interval del 95,5 %? La taula següent, on t10, t30..., t1600 representen
les distribucions t de Student amb 10, 30... 1600 graus de llibertat,
ho mostra:

Vegeu que per les mides de les mostres aconsellables en una enquesta adreçada a estimar una proporció la diferència és ben minsa. Podem prendre, doncs, com una excel·lent aproximació del
radi de l'interval de confiança (si el nivell de confiança
és del 95,5 % i la mida de la mostra és la usual en enquestes)
el valor de Així, s'arriba a l'enunciat sobre l'interval de confiança d'una estimació que s'ha donat al text.
|
|||||||||||||||
|
|
|||||||||||||||
|
|
Ampliació 3: Fórmules aplicables si es consideren mostres sense reemplaçament |
||||||||||||||
|
En canvi, si traiem boles sense reemplaçament, les extraccions no són independents i la probabilitat d'èxit va variant. Així, per exemple, si a la bossa hi ha N boles (mida de la població) i en la primera extracció la probabilitat de treure bola blanca és b/N, si la primera bola és blanca a la segona extracció la probabilitat serà (b-1)/(N-1), però si la primera no ha estat blanca la probabilitat que ho sigui la segona és b/(N-1), etc. Si el valor de N és molt gran, sovint les diferències són inapreciables, però si no ho és tant, llavors cal tenir-ho en compte. Per això, si es fa una enquesta sense reemplaçament, en aquest cas s'ha de considerar un factor de correcció en el radi de l'interval de confiança de l'estimació d'una proporció. En aquest factor intervé la mida de la població i les fórmules que s'han de considerar són les següents:
En aquestes fórmules k representa el valor crític segons el nivell de confiança i la distribució amb què vulguem treballar. Habitualment, és k = 2 si considerem el nivell de confiança del 95,5 % i l'aproximació donada per la distribució normal. Altrament, podeu consultar la taula corresponent una mica més amunt. Adoneu-vos d'alguns valors d'aquest factor de correcció:
|
|||||||||||||||
|
|
|||||||||||||||
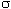 ). També
ens podem fixar en l'exemple del bombo: l'estimador màxim de
la mostra és esbiaixat. Si fem moltes mostres i calculem la mitjana
dels màxims nombres obtinguts en cada mostra, ben segur que obtenim
un valor menor que el nombre més gran que hi ha al bombo.
). També
ens podem fixar en l'exemple del bombo: l'estimador màxim de
la mostra és esbiaixat. Si fem moltes mostres i calculem la mitjana
dels màxims nombres obtinguts en cada mostra, ben segur que obtenim
un valor menor que el nombre més gran que hi ha al bombo.
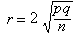 .
.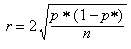 .
.

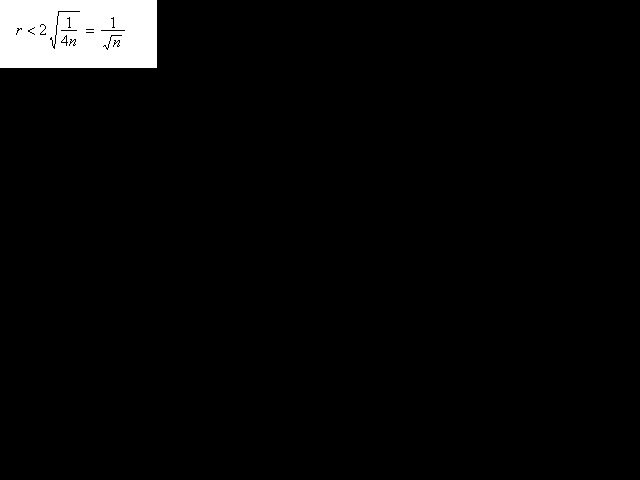
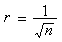 .
.